
It is not so easy to find databases with ASCII characterset in these days, at least in Europe we usually create our databases with UTF8 characterset..

In the scan phase, it may report invalid representation for the rows that have territory='KR' in XDO.XDO_TRANS_UNIT_VALUES table.
We update these rows as follows;
Update XDO.XDO_TRANS_UNIT_VALUES set value='CORRUPTED' where territory='KR'
After these update, it may report errors again.. This time for 4 rows...
For fixing these rows, we can use the editior..

R12.0 / R12.1 : Globalization Guide for Oracle Applications Release 12 (Doc ID 393861.1)
Also, when we talk about Turkey, I can say that we at least use WEISO8859P9 , which support turkish characters..
Meanwhile, the characterset that we need is not the only thing affecting our decision to choose a characterset..
Meanwhile, the characterset that we need is not the only thing affecting our decision to choose a characterset..
Nowadays, the new releases of the applications such as Hyperion require us to have a database with at least a UTF8 characterset.
Even so, as you may expect ; there are still some databases which come with ASCII character set by default..
The database bundled with EBS 12.2 template of Oracle is a good example for these kind of databases.
The database bundled with EBS 12.2 template of Oracle is a good example for these kind of databases.
It comes with a ASCII database, and that 's why it is impossible to apply an NLS Language patch on top of its application tier. In other words, it is not possible to make it support multi languages.(such as American and Turkish)
In the past, I remember that converting a characterset from one to another, was a big deal.. ( if the target is not a subset of the source)
Nowadays, fortuneatly, we use stable tools to convert our databases from ASCII to UTF8, AL32UTF8 etc... automatically, as you will see in the real example below..
Okay...We have done this conversion already 2 times for EBS 12.2, and I can say that it works..
So, If you have a virtualized Oracle environment ( like a virutalized ODA X4 our any hardware that runs Oracle VM Server ) , importing Oracle EBS 12.2 templates is a good way to deploy EBS 12.2..
You may find a real life EBS 12.2 template installation example in the following link:
http://ermanarslan.blogspot.com.tr/2014/05/ovm-oracle-vm-server-328-installation.html
It is fast and it requires less effort but you have got to consider converting the character set, too..
In the following example , we ll convert an ASCII EBS 12.2.3 database to AL32UTF8.
In the past, I remember that converting a characterset from one to another, was a big deal.. ( if the target is not a subset of the source)
Nowadays, fortuneatly, we use stable tools to convert our databases from ASCII to UTF8, AL32UTF8 etc... automatically, as you will see in the real example below..
Okay...We have done this conversion already 2 times for EBS 12.2, and I can say that it works..
So, If you have a virtualized Oracle environment ( like a virutalized ODA X4 our any hardware that runs Oracle VM Server ) , importing Oracle EBS 12.2 templates is a good way to deploy EBS 12.2..
You may find a real life EBS 12.2 template installation example in the following link:
http://ermanarslan.blogspot.com.tr/2014/05/ovm-oracle-vm-server-328-installation.html
It is fast and it requires less effort but you have got to consider converting the character set, too..
In the following example , we ll convert an ASCII EBS 12.2.3 database to AL32UTF8.
We do this operation using Oracle Database Migration Assistant for Unicode (DMU) as follows...
http://www.oracle.com/technetwork/database/database-technologies/globalization/dmu/learnmore/start-334681.html
First, we install the required PL/SQL package in the database:
start an SQL*Plus session in the Oracle Home of your database,
log in with SYSDBA credentials, and run the script prvtdumi.plb as follows;
$ sqlplus / as sysdba
SQL*Plus: Release 11.2.0.2.0 Production
Copyright (c) 1982, 2010, Oracle. All rights reserved.
Connected to:Oracle Database 11g Enterprise Edition Release 11.2.0.2.0 -ProductionWith the Partitioning, Oracle Label Security, OLAP, Data Miningand Real Application Testing options
SQL>@?/rdbms/admin/prvtdumi.plb
Library created.
Package created.
No errors.
Package body created.
No errors.
Then download and install JDK6 : Note that, there is no need to install jdk, just set db environment and run dmu.
Next, download and install the DMU software:
The DMU is available from its OTN download page. It is also available from My Oracle Support (MOS) asPatch #18392374
To install the DMU, extract the downloaded archive into any target folder/directory using an un-ZIP utility for your platform.
Then, Start the tool:
$ chmod u+x dmu.sh
$ ./dmu.sh
Create a database connection:

Install the DMU repository:
If you connect to a database for the first time, the DMU automatically prompts you to install the repository. If you are not prompted to install the repository, you can install it by right-clicking the database you want to use, and selectingConfigureDMURepository. You can also selectConfigureDMURepositoryfrom the Migration menu. In all of these cases, the Repository Configuration Wizard appears.
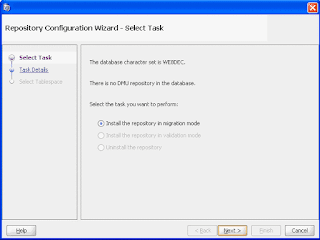
To install the Migration Repository:
On the first page of the wizard, the only choice available is Install the repository in migration mode. After selecting this, clickNext. After you clickNext, the second page of the Repository Configuration Wizard is shown.

Here, you select the target character set for the migration. You can choose AL32UTF8

On the third page, you can select the tablespace in which you want to install the repository.
Click finish to install the repository.
Now, you are ready to begin the migration process to Unicode, as described in the DMU documentation. You will scan the database to identify convertibility issues, cleanse the database from these issues, and run the actual conversion step.
Start the migration process
Scanning :


http://www.oracle.com/technetwork/database/database-technologies/globalization/dmu/learnmore/start-334681.html
First, we install the required PL/SQL package in the database:
start an SQL*Plus session in the Oracle Home of your database,
log in with SYSDBA credentials, and run the script prvtdumi.plb as follows;
$ sqlplus / as sysdba
SQL*Plus: Release 11.2.0.2.0 Production
Copyright (c) 1982, 2010, Oracle. All rights reserved.
Connected to:Oracle Database 11g Enterprise Edition Release 11.2.0.2.0 -ProductionWith the Partitioning, Oracle Label Security, OLAP, Data Miningand Real Application Testing options
SQL>@?/rdbms/admin/prvtdumi.plb
Library created.
Package created.
No errors.
Package body created.
No errors.
Then download and install JDK6 : Note that, there is no need to install jdk, just set db environment and run dmu.
Next, download and install the DMU software:
The DMU is available from its OTN download page. It is also available from My Oracle Support (MOS) asPatch #18392374
To install the DMU, extract the downloaded archive into any target folder/directory using an un-ZIP utility for your platform.
Then, Start the tool:
$ chmod u+x dmu.sh
$ ./dmu.sh
Create a database connection:

Install the DMU repository:
If you connect to a database for the first time, the DMU automatically prompts you to install the repository. If you are not prompted to install the repository, you can install it by right-clicking the database you want to use, and selectingConfigureDMURepository. You can also selectConfigureDMURepositoryfrom the Migration menu. In all of these cases, the Repository Configuration Wizard appears.

To install the Migration Repository:
On the first page of the wizard, the only choice available is Install the repository in migration mode. After selecting this, clickNext. After you clickNext, the second page of the Repository Configuration Wizard is shown.

Here, you select the target character set for the migration. You can choose AL32UTF8

On the third page, you can select the tablespace in which you want to install the repository.
Click finish to install the repository.
Now, you are ready to begin the migration process to Unicode, as described in the DMU documentation. You will scan the database to identify convertibility issues, cleanse the database from these issues, and run the actual conversion step.
Start the migration process
Scanning :



In the scan phase, it may report invalid representation for the rows that have territory='KR' in XDO.XDO_TRANS_UNIT_VALUES table.
We update these rows as follows;
Update XDO.XDO_TRANS_UNIT_VALUES set value='CORRUPTED' where territory='KR'
After these update, it may report errors again.. This time for 4 rows...
For fixing these rows, we can use the editior..
When we click on the problematic rows, the tool displays the problematic characters painted in red. We delete these characters and start a new scan.
Note that: You can not convert your characterset without correcting theses errors.
At the last step, we start the convert operation, and we are done.
Important: If you need to convert the Application Tier's characterset , you need to follows appendix A in the document below(Doc ID 393861.1)... On the other hand, this step is not required if you import an EBS 12.2 template..
Note that: You can not convert your characterset without correcting theses errors.
At the last step, we start the convert operation, and we are done.
Important: If you need to convert the Application Tier's characterset , you need to follows appendix A in the document below(Doc ID 393861.1)... On the other hand, this step is not required if you import an EBS 12.2 template..
The apps Tier of EBS 12.2 template already comes with an Apps Tier , which has UTF8 characterset.

R12.0 / R12.1 : Globalization Guide for Oracle Applications Release 12 (Doc ID 393861.1)
- We run dmu on our EBS 12.1.3 and report about 100 tables for data truncation for specific varchar2 columns
ReplyDelete- How to solve such data; For example table GL_JE_HEADERS Fields (NAME, DESCRIPTION) need to shorten data for such field before conversion , about 300,000 record
- DMU didn't give me ability to update data using Cleansing Editor (Editor is read only)
- Also Oracle didn't support me in that ; only said to use EBS User Interface to update such fields
Finally what is the best solution for such data truncation problem !!!
After dmu, Do you need to edit $CONTEXT_FILE and run autocfg.sh to reflect the char set change? If you edit run fs context file, how it will populate to patch fs? Thanks.
ReplyDelete